
Sidekiq at GitLab
GitLab is a Ruby-on-Rails application that processes a lot of data. Much of this processing can be done asynchronously, and one of the solutions we use to accomplish this is Sidekiq which is a background-processing framework for Ruby. It handles jobs that are better processed asynchronously outside the web request/response cycle.
There are a few terms that that we'll use in this post:
- A worker class is a class defined in our application to process a task in Sidekiq.
- A job is an instance of a worker class, so each job represents a single task.
- A queue is a collection of jobs (potentially for different worker classes) that are waiting to be processed.
- A worker thread is a thread processing jobs in particular queues. Each Sidekiq process can have multiple worker threads.
Then there are two terms specific to GitLab.com:
- A Sidekiq role is a configuration for a particular group of queues. For instance, we might have a
push_actionsrole that is for processing thepost_receiveandprocess_commitqueues. - A Sidekiq node is an instance of the GitLab application for a Sidekiq role. A Sidekiq node can have multiple Sidekiq processes.
Back in 2013, in version 6.3 of GitLab, every Sidekiq worker class had its own queue. We weren't strict in monitoring the creation of new worker classes. There was no strategic plan for assigning queues to where they would execute.
In 2016, we tried to introduce order again, and rearranged the queues to be based on features. We followed this with a change in
2017 to have a dedicated queue for each worker class again, and we were able to monitor queues more accurately and impose specific
throttles and limits to each. It was easy to quickly make decisions about the queues as they were running because of how
the work was distributed. The queues were grouped, and the names of these groups were realtime, asap, and besteffort for example.
At the time, we knew that this was not the approach recommended by the author of Sidekiq, Mike Perham, but we felt that we knew what the trade-offs were. In fact, Mike wrote:
“I don't recommend having more than a handful of queues. Lots of queues makes for a more complex system and Sidekiq Pro cannot reliably handle multiple queues without polling. M Sidekiq Pro processes polling N queues means O(M*N) operations per second slamming Redis.”
From https://github.com/mperham/sidekiq/wiki/Advanced-Options#queues
This served us well for nearly two years before this approach no longer matched our scaling needs.
Pressure from availability issues
In mid-2019 GitLab.com experienced several different major incidents related to the way we process background queues.
Examples of these incidents:
- Gitaly n+1 calls caused bad latency and resulted in the Sidekiq queues growing. This was due to the way we processed tags in Gitaly.
- A user generated many notes on a single commit which slowed down the new_note Sidekiq queue and led to a delay of sending out notifications.
- CI jobs took very long to complete because jobs in the pipeline_processing:pipeline_process Sidekiq queue piled up. 2 pipelines caused a high amount of Sidekiq jobs, Sidekiq pipeline nodes were maxing out their CPU, pipeline_processing jobs were causing many SQL calls and the pgbouncer pool for Sidekiq was becoming saturated.
All of these were showing that we needed to take action.
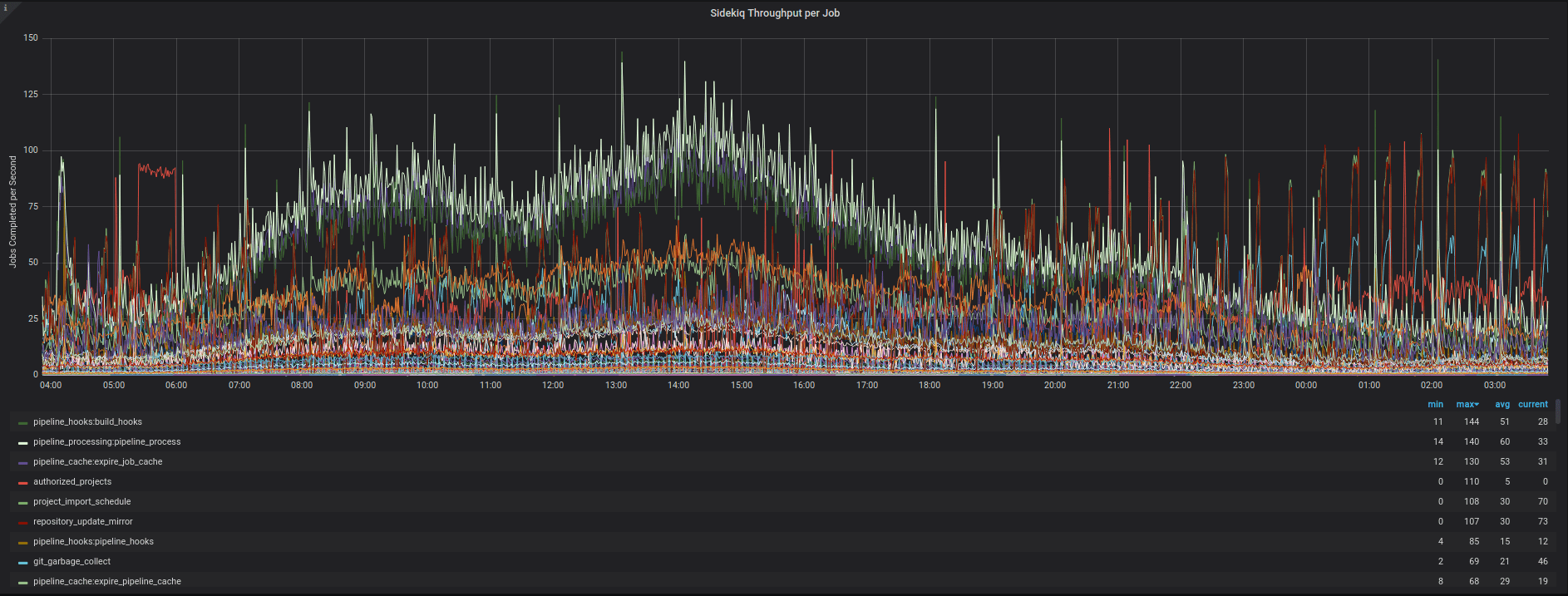
This image shows how many jobs we process per second over a 24 hour period. This shows the variety of jobs and gives an idea of the scale of jobs in relation to each other.
Improvements
Changing the relationship between jobs and Sidekiq roles
In infrastructure#7219 (closed) we significantly altered our approach for how jobs were related to Sidekiq roles.
We started from a position where:
- We had a many-to-many relationship between Sidekiq jobs and Sidekiq roles.
- For example, most pipeline jobs ran on the
besteffortnodes, but some ran on the pipeline nodes. - Some jobs ran on up to three types of node: eg
realtime,asapandbesteffortpriorities.
- For example, most pipeline jobs ran on the
- Worker threads were reserved for single queues.
- For example, one eighth of the
realtimequeue might be reserved for new_note jobs. In the event of a glut of new_note jobs, most of the fleet would sit idle while one worker thread would be saturated. Worse, adding more nodes would only increase processing power by 1/8th of a node, not the full compute capacity of the new node.
- For example, one eighth of the
- Urgent and non-urgent jobs would be in the same queue.
- For example, some jobs in the
realtimequeue would take up to 10 minutes to process. - This is a bit like allowing overloaded trolleys in the 10 items-or-less lane.
- For example, some jobs in the
Once the issue was completed, we now had:
- A one-to-one relationship between Sidekiq jobs and Sidekiq roles
- Each job will execute on exactly one Sidekiq role
- All worker threads will run all jobs, and each Sidekiq node will have the same number of worker threads
- When a glut of jobs comes in, 100% of compute on a node can be dedicated to executing the jobs
- Slow jobs and fast jobs are kept apart
- The 10 items or less lane is now being enforced.
While this was a significant improvement, it introduced some technical debt. We fixed everything for a moment in time, knowing that as soon as the application changed this would be out of date, and as time went on, would only get more out of date until we were back in the same position. To try and mitigate this in future, we started to look at classifying the workloads and using queue selectors.
Queue Selectors Deployed in Sidekiq Cluster
In the Background Processing Improvements Epic, we looked at ways that we could simplify the structure so that background processing could be in a position to scale to 100x the traffic at the time. We also needed the processing to be unsurprising. Operators (and developers) should understand where a job will run, why it is queueing up and how to reduce queues. We decided to move to using queue selectors to help us to keep the queue definitions correct. (This approach is still experimental).
In addition, the infrastructure team should not reactively (and manually) route Sidekiq jobs to priority fleets, as was the situation previously. Developers should have the ability to specify the requirements of their workloads and have these automatically processed on a queue designed to support that type of work.
Sidekiq processes can be configured to select specific queues for processing. Instead of making this selection by name, we wanted to make the selection on how the workload for that queue was classified.
We came up with an approach for classifying background jobs by their workload and building a sustainable way of grouping similar workloads together.
When a new job is created, developers need to do this to classify the workload. This is done through
- Specifying the urgency of the job. The options
are
high,lowandnone. If the delay of a job would have user impact, then the job ishighurgency. - Noting if the job has external dependencies that could impact their availability. (For example, if they communicate with user-specified Kubernetes clusters).
- Adding an annotation declaring if the worker class will be cpu-bound or memory-bound. Knowing this allows us to make decisions around how much thread concurrency a Ruby process can tolerate, or targeting memory-bound jobs to low-concurrency, high-memory nodes.
There is additional guidance available to determine if the worker class should be marked as cpu-bound.
SLAs are based on these attributes
- High urgency jobs should not queue for more than 10 seconds.
- High urgency jobs should not take more than 10 seconds to execute (this SLA is the responsibility of the owning team to ensure that high throughput is maintained).
- Low urgency jobs should not queue for more than 1 minute.
- Jobs without urgency have no queue SLA.
- Non-high urgency jobs should not take more than 5 minutes to execute.
In each case, the queuing SLAs are the responsibility of the infrastructure team, as they need to ensure that the fleet is correctly provisioned to meet the SLA.
The execution latency SLAs are the responsibility of the development team owning the worker class, as they need to ensure that the worker class is sufficiently performant to ensure throughput.
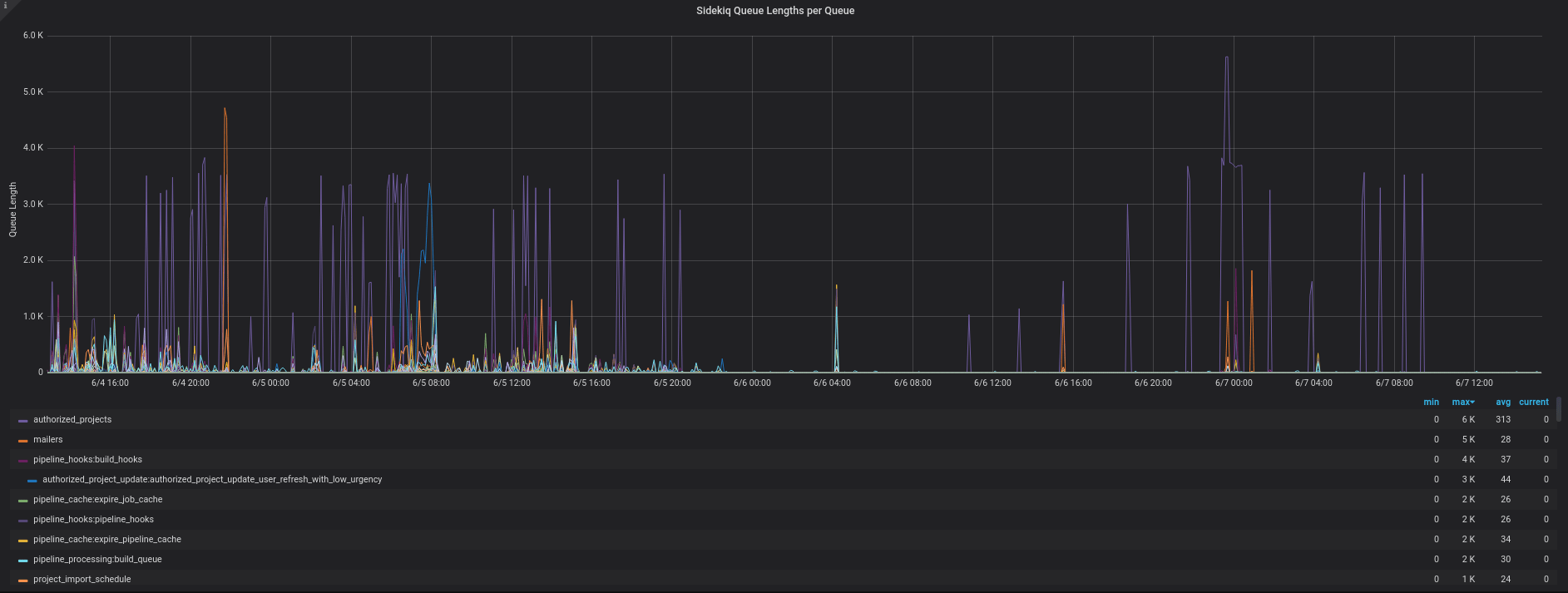
This image shows the challenges we faced by having jobs of different urgency running on the same queue. The purple lines show spikes from one particular worker, where many jobs were added to the queue, causing delays to other jobs which were often of equal or higher importance.
Challenge during rollout - BRPOP
As the number of background queues in the GitLab application grows, this approach continues to burden our Sidekiq Redis
servers. On GitLab.com, our catchall Sidekiq nodes monitor about 200 queues, and the Redis BRPOP
commands used to monitor the queues consume a significant amount of time (by Redis latency standards).
The number of clients listening made this problem worse. For besteffort we had 7 nodes, each running 8 processes,
with 15 threads watching those queues - meaning 840 clients.
The command causing the problem was BRPOP. The time taken to perform this command also relates to the number of listeners on those keys. The addition of multiple keys increases contention in the system which causes lots of connections to block. And when the key list is longer the problem gets worse. The keylist represents the number of queues, the more queues we have, the more keys we are listening to. We saw this problem on the nodes that process the most queues.
We raised an issue in the Redis issue tracker about the performance we observed when many clients performed BRPOP on the same key. It was fantastic when Salvatore responded within the hour and the patch was available the same day! This fix was made in Redis 6 and backported to Redis 5. Omnibus has also been upgraded to use this fix, and it will be available in the major release 13.0.
Current State (as of June 2020)
Migrating to these new selectors has been completed as of late April 2020.
We reduced our Sidekiq fleet from 49 nodes with 314 CPUs, to 26 nodes with 158 CPUs. This has also reduced our cost. The average utilization is more evenly spread across the new fleets.
Also, we have moved Sidekiq-cluster to Core. Previously, running Sidekiq in clustered mode (i.e. spawning more than one process) was technically only available as part of GitLab EE distributions, and for self-managed environments only in the Starter+ tiers. Because of that, when booting Sidekiq up in a development env with the GDK, the least common denominator was assumed, which was to run Sidekiq in a single-process setup. That can be a problem, because it means there is a divergence between the environment developers work on, and what will actually run in production (i.e. gitlab.com and higher-tier self-managed environments).
In release 13.0 Sidekiq Cluster is used by default.
We’re also better placed to migrate to Kubernetes. The selector approach is a lot more compatible with making good decisions about things like CPU allocations + limits for Kubernetes workloads, and this will make the job of our delivery team easier, leading to further cost reductions from auto-scaling deployed resources to match actual load.
Our next piece of work with Sidekiq will be to reduce the number of queues that we need to watch and we will post a follow-up to this blog post when the work is completed.
Read more about infrastructure issues:
Keep Kubernetes runners moving
Understand parent-child pipelines
Cover image by Jerry Zhang on Unsplash


