
Continuous integration (CI) is standard practice in software development for speeding up development cycles, and for keeping them short and painless. CI means making small commits, often, and automating tests so every commit is a release candidate.
When a project involves machine learning (ML), though, new challenges arise: Traditional version control systems (like Git) that are key to CI struggle to manage large datasets and models. Furthermore, typical pass-fail tests are too coarse for understanding ML model performance – you might need to consider how several metrics, like accuracy, sensitivity, and specificity, are affected by changes in your code or data. Data visualizations like confusion matrices and loss plots are needed to make sense of the high-dimensional and often unintuitive behavior of models.
Continuous machine learning: an introduction
Iterative.ai, the team behind the popular open source version control system for ML projects DVC (short for Data Version Control), has recently released another open source project called CML, which stands for continuous machine learning. CML is our approach to adapting powerful CI systems like GitLab CI to common data science and ML use cases, including:
- Automatic model training
- Automatic model and dataset testing
- Transparent and rich reporting about models and datasets (with data viz and metrics) in a merge request (MR)
Your first continuous machine learning report
CML helps you put tables, data viz, and even sample outputs from models into comments on your MRs, so you can review datasets and models like code. Let's see how to produce a basic report – we'll train an ML model using GitLab CI, and then report a model metric and confusion matrix in our MR.
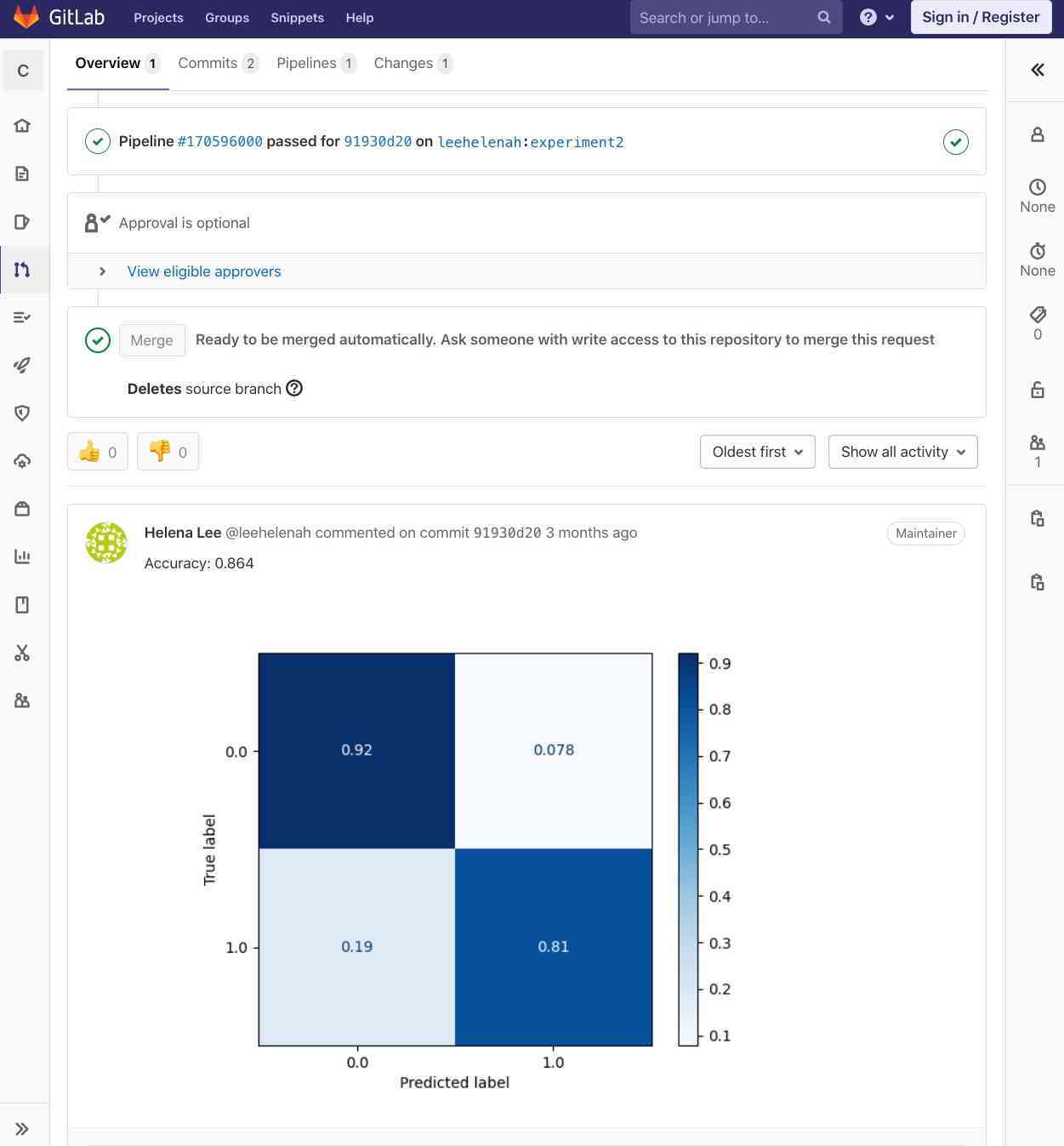 Confusion matrix
Confusion matrix
To make this report, our .gitlab-ci.yml contains the following workflow:
# .gitlab-ci.yml
stages:
- cml_run
cml:
stage: cml_run
image: dvcorg/cml-py3:latest
script:
- pip3 install -r requirements.txt
- python train.py
- cat metrics.txt >> report.md
- echo >> report.md
- cml-publish confusion_matrix.png --md --title 'confusion-matrix' >> report.md
- cml-send-comment report.md
The entire project repository is available here. The steps consist of the following:
- Train: This is a classic training step where we install requirements (like
pippackages) and run the training script. - Write a CML report: Produced metrics are appended to a markdown report.
- Publish a CML report: CML publishes an image of the confusion matrix with the embedded metrics to your GitLab MR.
Now, when you and your teammates are deciding if your changes have had a positive effect on your modeling goals, you have a dashboard of sorts to review. Plus, this report is linked by Git to your exact project version (data and code) and the runner used for training and the logs from that run.
This is the simplest use case for achieving continuous machine learning with CML and GitLab. In the next section we'll look at a more complex use case.
CML with DVC for data version control
In machine learning projects, you need to track changes in your datasets as well as changes in your code. Since Git is frequently a poor fit for managing large files, we can use DVC to link remote datasets to your CI system.
# .gitlab-ci.yml
stages:
- cml_run
cml:
stage: cml_run
image: dvcorg/cml-py3:latest
script:
- dvc pull data
- pip install -r requirements.txt
- dvc repro
# Compare metrics to master
- git fetch --prune
- dvc metrics diff --show-md master >> report.md
- echo >> report.md
# Visualize loss function diff
- dvc plots diff
--target loss.csv --show-vega master > vega.json
- vl2png vega.json | cml-publish --md >> report.md
- cml-send-comment report.md
The entire project is available here. In this workflow, we have additional steps that use DVC to pull a training dataset, run an experiment, and then use CML to publish the report in your MR.
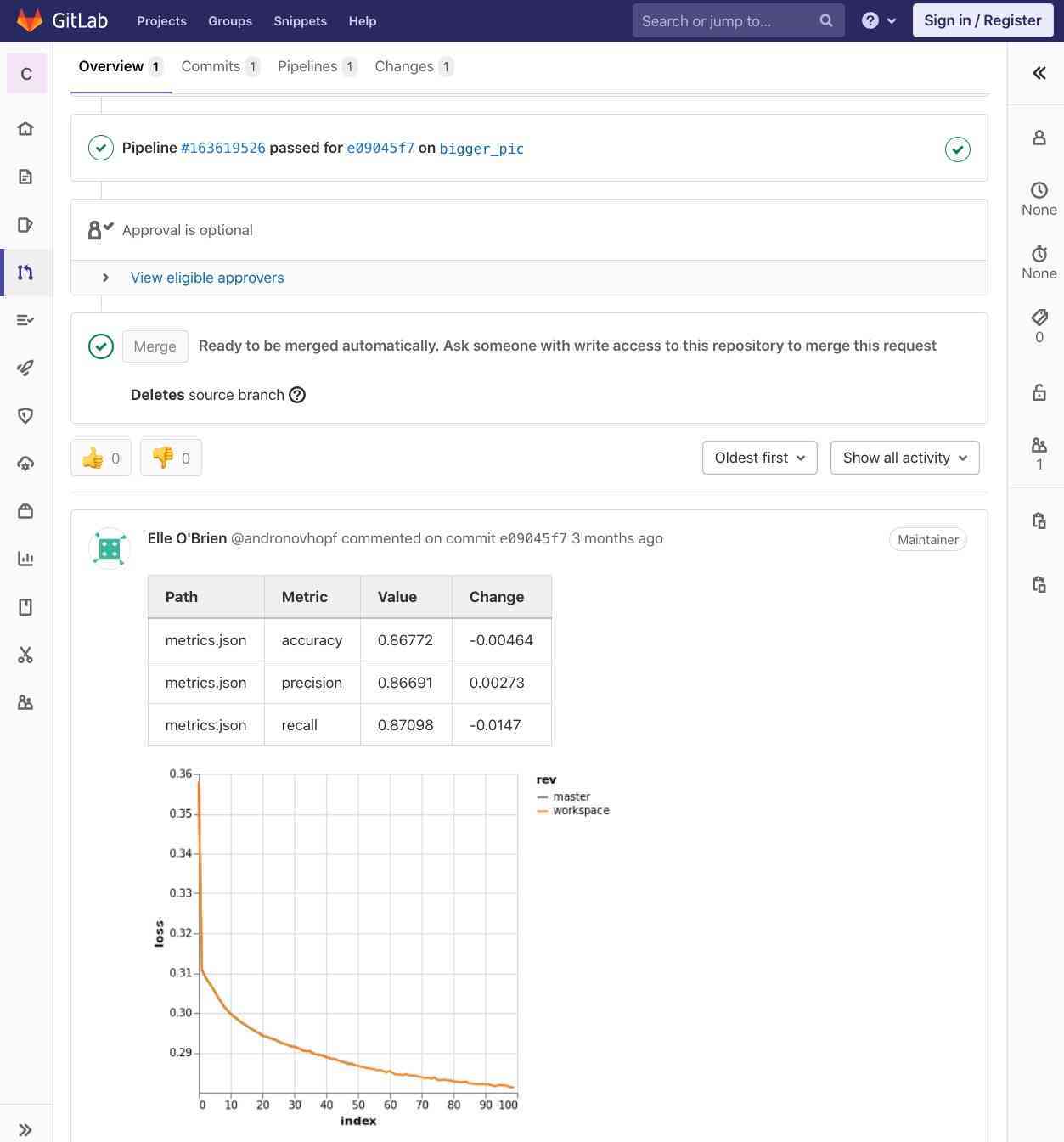 CML with DVC
CML with DVC
For more details about ML data versioning and tracking, check out the DVC documentation.
Summary
We made CML to adapt CI to machine learning, so data science teams can enjoy benefits such as:
- Your code, data, models, and training infrastructure (hardware and software environment) will be Git versioned.
- You’re automating work, testing frequently, and getting fast feedback (with visual reports if you use CML). In the long run, this will almost certainly speed up your project’s development.
- CI systems make your work visible to everyone on your team. No one has to search very hard to find the code, data, and model from your best run.
About the guest author
Dr. Elle O'Brien is a Ph.D data scientist at iterative.ai and co-creator of CML project. She is also a lecturer at UMSI.


