
In this post we look back on a series of projects from the Scalability team that improved GitLab server-side efficiency for serving Git fetch traffic. In the benchmark described below we saw a 9x reduction in GitLab server CPU utilization. Most of the performance comes from the Gitaly pack-objects cache, which has proven very effective at reducing the Gitaly server load caused by highly concurrent CI pipelines.
These changes are not user-visible but they benefit the stability and availability of GitLab.com. If you manage a GitLab instance yourself you may want to enable the pack-objects cache on your instance too.
We discuss how we achieved these improvements in part 2.
Background
Within the GitLab application, Gitaly is the component that acts as a remote procedure call (RPC) server for Git repositories. On GitLab.com, repositories are stored on persistent disks attached to dedicated Gitaly servers, and the rest of the application accesses repositories by making RPC calls to Gitaly.
In 2020 we encountered several incidents on GitLab.com caused by the fact that
our Gitaly server infrastructure could not
handle
the Git fetch traffic generated by CI on our own main repository,
gitlab-org/gitlab. The only reason the situation at the time worked
was because we had a custom CI caching solution for
gitlab-org/gitlab only, commonly referred to as the "CI pre-clone
script".
The CI pre-clone script
The CI pre-clone script was an implementation of the clone bundle CI fetching strategy. We had originally set up the CI pre-clone script one year earlier, in December 2019. It consisted of two parts.
- A CI cron job that would clone
gitlab-org/gitlab, pack up the result into a tarball, and upload it to a known Google Cloud Storage bucket. - A shell script snippet, stored in the
gitlab-org/gitlabproject settings, that was injected into eachgitlab-org/gitlabCI job. This shell script would download and extract the latest tarball from the known URL. After that the CI job did an incremental Git fetch, relative to the tarball contents, to retrieve the actual CI pipeline commit.
This system was very effective. Our CI pipelines run against shallow
Git clones of gitlab-org/gitlab, which require over 100MB of data to
be transfered per CI job. Because of the CI pre-clone script, the
amount of Git data per job was closer to 1MB. The rest of the data was
already there because of the tarball. The amount of repository data
downloaded by each CI job stayed the same, but only 1% of this data
had to come from a Gitaly server. This saved a lot of computation and
bandwidth on the Gitaly server hosting gitlab-org/gitlab.
Although this solution worked well, it had a number of downsides.
- It was not part of the application and required per-project manual set-up and maintenance.
- It did not work for forks of
gitlab-org/gitlab. - It had to be maintained in two places: the project that created the
tarball and the project settings of
gitlab-org/gitlab. - We had no version control for the download script; this was just text stored in the project's CI settings.
- The download script was fragile. We had one case where we added an
exitstatement in the wrong place, and allgitlab-org/gitlabbuilds started silently using stale checkouts left behind by other pipelines. - In case of a Google Cloud Storage outage, the full uncached traffic
would saturate the Gitaly server hosting
gitlab-org/gitlab. Such outages are rare but they do happen. - A user who would want to copy our solution would have to set up their own Google Cloud Storage bucket and pay the bills for it.
The biggest issue really was that one year on, the CI pre-clone script had not evolved from a custom one-off solution into an easy to use feature for everyone.
We solved this problem by building the pack-objects cache, which we will describe in more detail in the next blog post. Unlike the CI pre-clone script, which was a separate component, the pack-objects cache sits inside Gitaly. It is always on, for all repositories and all users on GitLab.com. If you run your own GitLab server you can also use the pack-objects cache, but you do have to turn it on first.
Performance comparison
To illustrate what has changed we have created a benchmark. We set up a GitLab
server with a clone of gitlab-org/gitlab on it, and we configured a
client machine to perform 20 simultaneous shallow clones of the same commit using Git HTTP.[^ssh] This
simulates having a CI pipeline with 20 parallel jobs. The pack data is
about 87MB so in terms of bandwidth, we are transferring 20 * 87 = 1740MB of data.
[^ssh]: As of GitLab 14.6, Git HTTP is 3x more CPU-efficient on the server than Git SSH. We are working on improving the efficiency of Git SSH in GitLab. We prioritized optimizing Git HTTP because that is what GitLab CI uses.
We did this experiment with two GitLab servers. Both were Google
Compute Engine c2-standard-8 virtual machines with 8 CPU cores and
32GB RAM. The operating system was Ubuntu 20.04 and we installed
GitLab using our Omnibus packages.
Before
- GitLab FOSS 13.7.9 (released December 2020)
- Default Omnibus configuration
The 30-second Perf flamegraph below was captured at 99Hz across all CPU's.
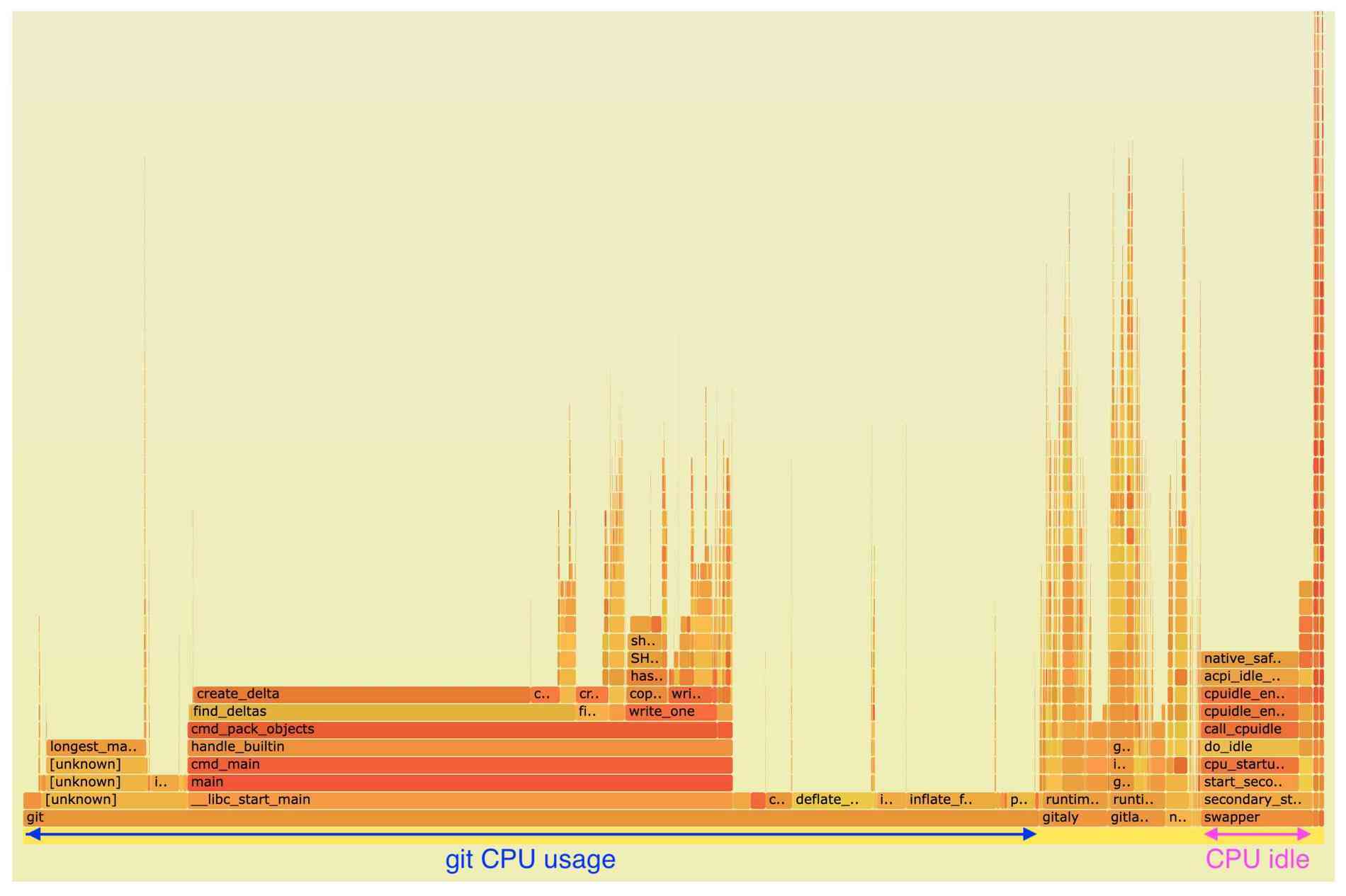
Source: SVG
After
- GitLab FOSS 14.6.1 (released December 2021)
- One extra setting in
/etc/gitlab/gitlab.rb:
gitaly['pack_objects_cache_enabled'] = true

Source: SVG
Analysis
Server CPU profile distribution:
| Value | Before | After |
|---|---|---|
| Benchmark run time | 27s | 7.5s |
git profile samples |
18 552 | 923 |
gitaly samples (Git RPC server process) |
1 247 | 331 |
gitaly-hooks samples (pack-objects cache client) |
258 | |
gitlab-workhorse samples (application HTTP frontend) |
1 057 | 237 |
nginx samples (main HTTP frontend) |
474 | 251 |
| Total CPU busy samples | 21 720 | 2 328 |
| CPU utilization during benchmark | 100% | 40% |
Conclusion
Compared to GitLab 13.6 (December 2020), GitLab 14.6 (December 2021) plus the pack-objects cache makes the CI fetch benchmark in this post run 3.6x faster. Average server CPU utilization during the benchmark dropped from 100% to 40%.
Stay tuned for part 2 of this blog post, in which we will go over the changes we made to make this happen.



{kind=link}
{kind=link}