
Building predictive models requires a good amount of experimentation and iterations. Data scientists building those models usually implement workflows involving several steps such as data loading, processing, training, testing, and deployment. Such workflows or data science pipelines come with a set of challenges on their own; some of these common challenges are:
- prone to error due to manual steps
- experimentation results that are hard to replicate
- long training time of machine learning (ML) models
When there is a challenge, there is also an opportunity; in this case, those challenges represent an opportunity for data scientists to adopt DevSecOps practices and enjoy the benefits of automation, repeatable workflows, standardization, and automatic provisioning of infrastructure needed for data-driven applications at scale.
The Data Science team at GitLab is now utilizing the GitLab DevSecOps Platform in their workflows, specifically to:
- enhance experiment reproducibility by ensuring code and data execute in a standardized container image
- automate training and re-training of ML models with GPU-enabled CI/CD
- leverage ML experiment tracking, storing the most relevant metadata and artifacts produced by data science pipelines automated with CI
At GitLab, we are proponents of "dogfooding" our platform and sharing how we use GitLab to build GitLab. What follows is a detailed look at the Data Science team's experience.
Enhancing experiment reproducibility
A baseline step to enhance reproducibility is having a common and standard experiment environment for all data scientists to run experiments in their Jupyter Notebooks. A standard data science environment ensures that all team members use the same software dependencies. A way to achieve this is by building a container image with all the respective dependencies under version control and re-pulling it every time a new version of the code is run. This process is illustrated in the figure below:
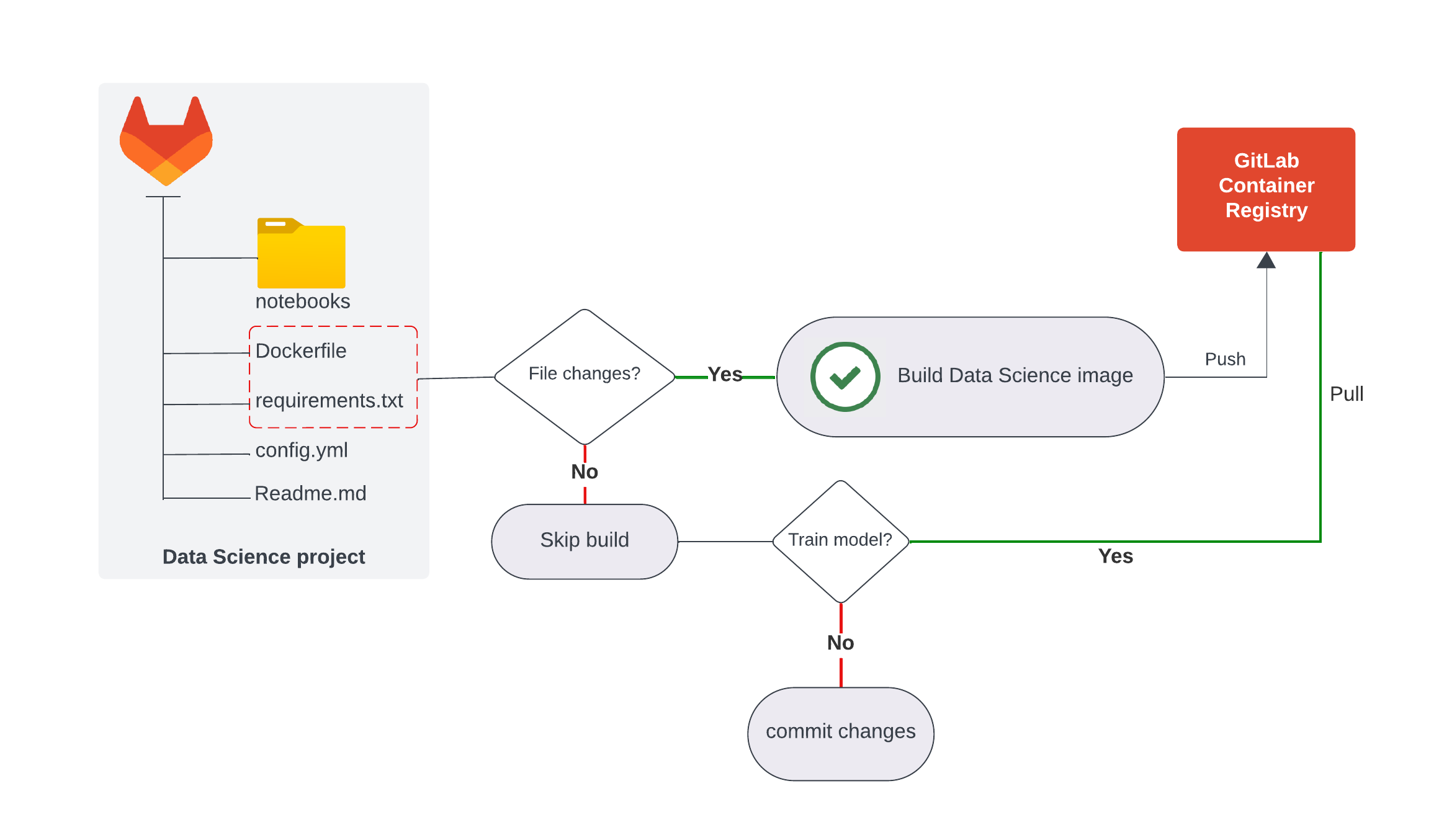 Data science image of automatic build using GitLab CI
Data science image of automatic build using GitLab CI
You might wonder if the image gets built every time there is a new commit. The answer is "no" since that would result in longer execution times, and the image dependencies versions don’t change frequently, rendering it unnecessary to build it every time there is a new commit. Therefore, once the standard image is automatically built by the pipeline, it is pushed to the GitLab Container Registry, where it is stored and ready to be pulled every time changes to the model code are introduced, and re-training is necessary.
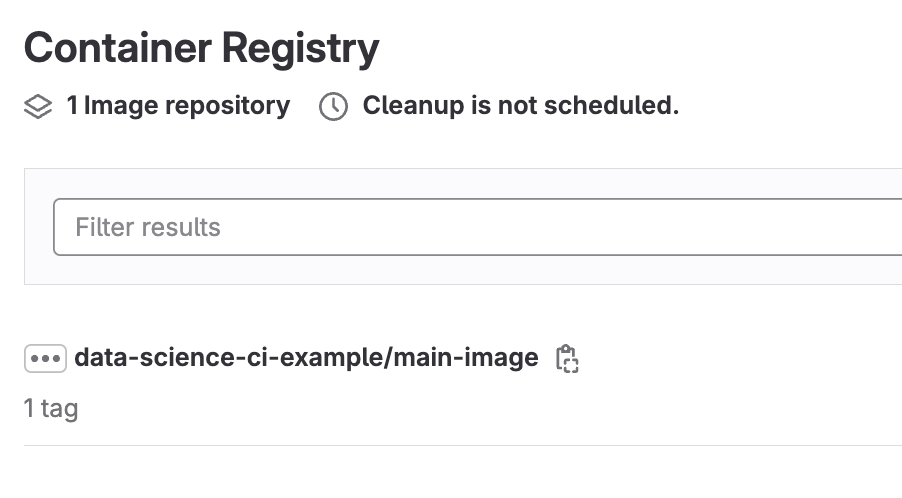 GitLab Container Registry with image automatically built and pushed by a CI pipeline
GitLab Container Registry with image automatically built and pushed by a CI pipeline
Changes to the image dependencies or Dockerfile require a merge request and an approval process.
How to build the data science image using GitLab CI/CD
Consider this project structure:
notebooks/
.gitlab-ci.yml
Dockerfile
config.yml
requirements.txt
GitLab's Data Science team already had a pre-configured JupyterLab image with packages such as gitlabds for common data preparation tasks and modules to enable Snowflake connectivity for loading raw data. All these dependencies are reflected in the Dockerfile at the root of the project, plus all the steps necessary to build the image:
FROM nvcr.io/nvidia/cuda:12.1.1-base-ubuntu22.04
COPY . /app/
WORKDIR /app
RUN apt-get update
RUN apt-get install -y python3.9
RUN apt-get install -y python3-pip
RUN pip install -r requirements.txt
The instructions to build the data science image start with using Ubuntu with CUDA drivers as a base image. We are using this baseline image because, moving forward, we will use GPU hardware to train models. The rest of the steps include installing Python 3.9 and the dependencies listed in requirements.txt with their respective versions.
Automatically building the data science image using GitLab CI/CD requires us to create the .gitlab-ci.yml at the root of the project and use it to describe the jobs we want to automate. For the time being, let’s focus only on the build-ds-imagejob:
variables:
DOCKER_HOST: tcp://docker:2375
MOUNT_POINT: "/builds/$CI_PROJECT_PATH/mnt"
CONTAINER_IMAGE: "$CI_REGISTRY_IMAGE/main-image:latest"
stages:
- build
- train
- notify
include:
- template: 'Workflows/MergeRequest-Pipelines.gitlab-ci.yml'
workflow:
rules:
- if: $CI_PIPELINE_SOURCE == "merge_request_event"
- if: $CI_COMMIT_BRANCH && $CI_OPEN_MERGE_REQUESTS
when: never
build-ds-image:
tags: [ saas-linux-large-amd64 ]
stage: build
services:
- docker:20.10.16-dind
image:
name: docker:20.10.16
script:
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $CI_REGISTRY
- docker build -t $CONTAINER_IMAGE .
- docker push $CONTAINER_IMAGE
rules:
- if: '$CI_PIPELINE_SOURCE == "merge_request_event" && $CI_MERGE_REQUEST_TARGET_BRANCH_NAME == $CI_DEFAULT_BRANCH'
changes:
- Dockerfile
- requirements.txt
allow_failure: true
At a high level, the job build-ds-image:
- uses a docker-in-docker service (dind) necessary to create docker images in GitLab CI/CD.
- uses predefined variables to log into the GitLab Container Registry, build the image, tag it using $CONTAINER_IMAGE variable, and push it to the registry. These steps are declared in the script section lines.
- leverages a
rulessection to evaluate conditions to determine if the job should be created. In this case, this job runs only if there are changes to the Dockerfile and requirements.txt file and if those changes are created using a merge request.
The conditions declared in rules helps us optimize the pipeline running time since the image gets rebuilt only when necessary.
A complete pipeline can be found in this example project, along with instructions to trigger the automatic creation of the data science image: Data Science CI pipeline.
Automate training and re-training of ML models with GPU-enabled CI/CD
GitLab offers the ability to leverage GPU hardware and, even better, to get this hardware automatically provisioned to run jobs declared in the .gitlab-ci.yml file. We took advantage of this capability to train our ML models faster without spending time setting up or configuring graphics card drivers. Using GPU hardware (GitLab Runners) requires us to add this line to the training job:
tags:
- saas-linux-medium-amd64-gpu-standard
The tag above will ensure that a GPU GitLab Runner automatically picks up every training job. Let’s take a look at the entire training job in the .gitlab-ci.yml file and break down what it does:
train-commit-activated:
stage: train
image: $CONTAINER_IMAGE
tags:
- saas-linux-medium-amd64-gpu-standard
script:
- echo "GPU training activated by commit message"
- echo "message passed is $CI_COMMIT_MESSAGE"
- notebookName=$(echo ${CI_COMMIT_MESSAGE/train})
- echo "Notebook name $notebookName"
- papermill -p is_local_development False -p tree_method 'gpu_hist' $notebookName -
rules:
- if: '$CI_COMMIT_BRANCH == "staging"'
when: never
- if: $CI_COMMIT_MESSAGE =~ /\w+\.ipynb/
when: always
allow_failure: true
artifacts:
paths:
- ./model_metrics.md
Let’s start with this block:
train-commit-activated:
stage: train
image: $CONTAINER_IMAGE
tags:
- saas-linux-medium-amd64-gpu-standard
- train-commit-activated This is the name of the job. Since the model training gets activated given a specific pattern in the commit message, we use a descriptive name to easily identify it in the larger pipeline.
- stage: train This specifies the pipeline stage where this job belongs. In the first part of the CI/CD configuration, we defined three stages for this pipeline:
build,train, andnotify. This job comes after building the data science container image. The order is essential since we first need the image built to run our training code in it. - image: $CONTAINER_IMAGE Here, we specify the Docker image built in the first job that contains the CUDA drivers and necessary Python dependencies to run this job. $CONTAINER_IMAGE is a user-defined variable specified in the variables section of the .gitlab-ci.yml file.
- tags: saas-linux-medium-amd64-gpu-standard As mentioned earlier, using this line, we ask GitLab to automatically provision a GPU-enabled Runner to execute this job.
The second block of the job:
script:
- echo "GPU training activated by commit message"
- echo "message passed is $CI_COMMIT_MESSAGE"
- notebookName=$(echo ${CI_COMMIT_MESSAGE/train})
- echo "Notebook name $notebookName"
- papermill -p is_local_development False -p tree_method 'gpu_hist' $notebookName -
- script This section contains the commands in charge of running the model training. The execution of this job is conditioned to the contents of the commit message. The commit message must have the name of the Jupyter Notebook that contains the actual model training code.
The rationale behind this approach is that we wanted to keep the data scientist workflow as simple as possible. The team had already adopted the modeling templates to start building predictive models quickly. Plugging the CI pipeline into their modeling workflow was a priority to ensure productivity would remain intact. With these steps:
notebookName=$(echo ${CI_COMMIT_MESSAGE/train})
- echo "Notebook name $notebookName"
- papermill -p is_local_development False -p tree_method 'gpu_hist' $notebookName -
The CI pipeline captures the name of the Jupyter Notebook with the training modeling template and passes parameters to ensure XGBoost uses the provisioned GPU. You can find an example of the Jupyter modeling template that is executed in this job here.
Once the data science image is built, it can be reutilized in further model training jobs. The train-commit-activated job pulls the image from the GitLab Container Registry and utilizes it to run the ML pipeline defined in the training notebook. This is illustrated in the CI Job - Train model in the figure below:
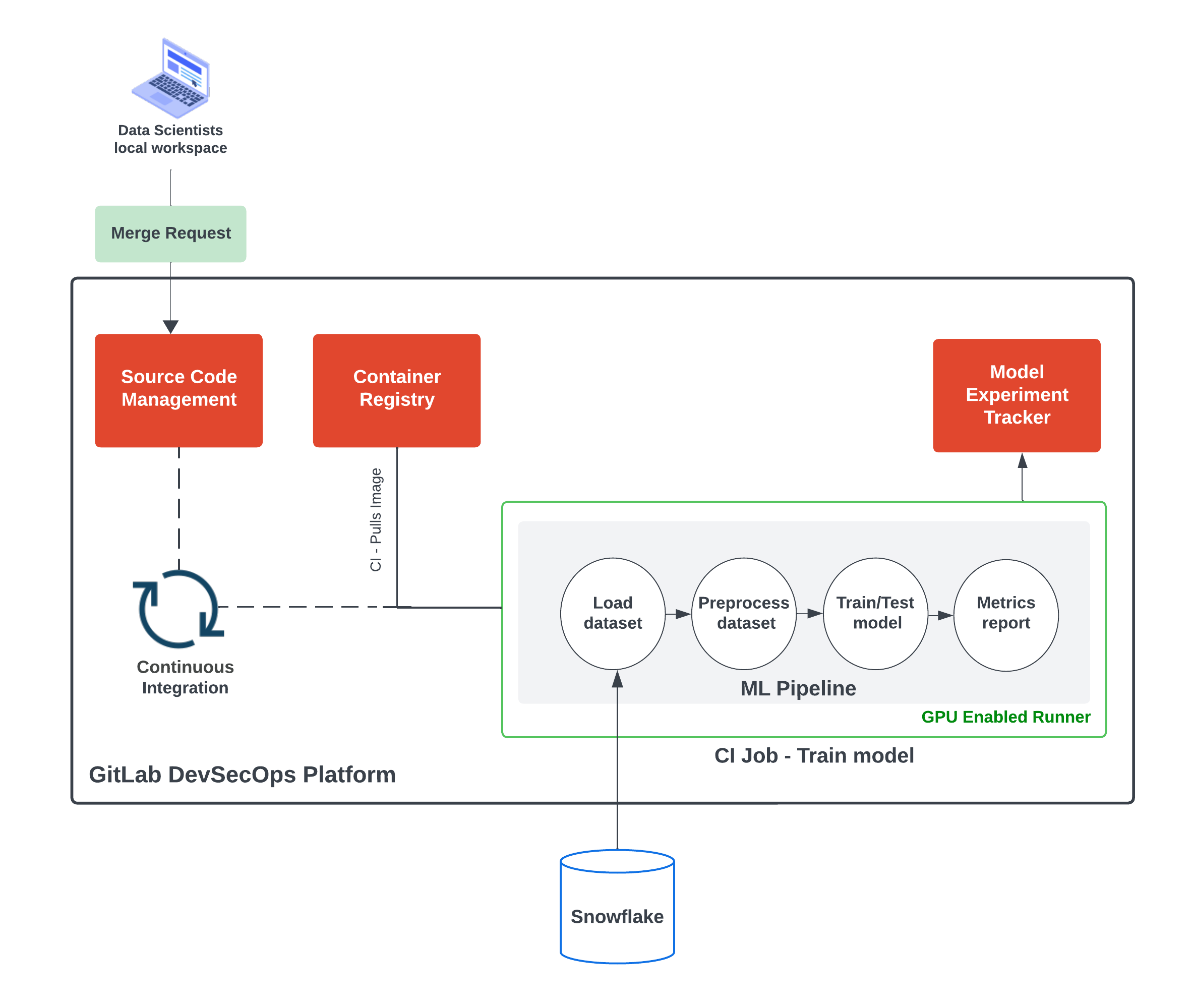 Training job executes ML pipeline defined in the modeling notebook
Training job executes ML pipeline defined in the modeling notebook
Since our image contains CUDA drivers and GitLab automatically provisions GPU-enabled hardware, the training job runs significantly faster with respect to standard hardware.
Using GitLab ML experiment tracker
Each model training execution triggered using GitLab CI is an experiment that needs tracking. Using Experiment tracking in GitLab helps us to record metadata that comes in handy to compare model performance and collaborate with other data scientists by making result experiments available for everyone and providing a detailed history of the model development.
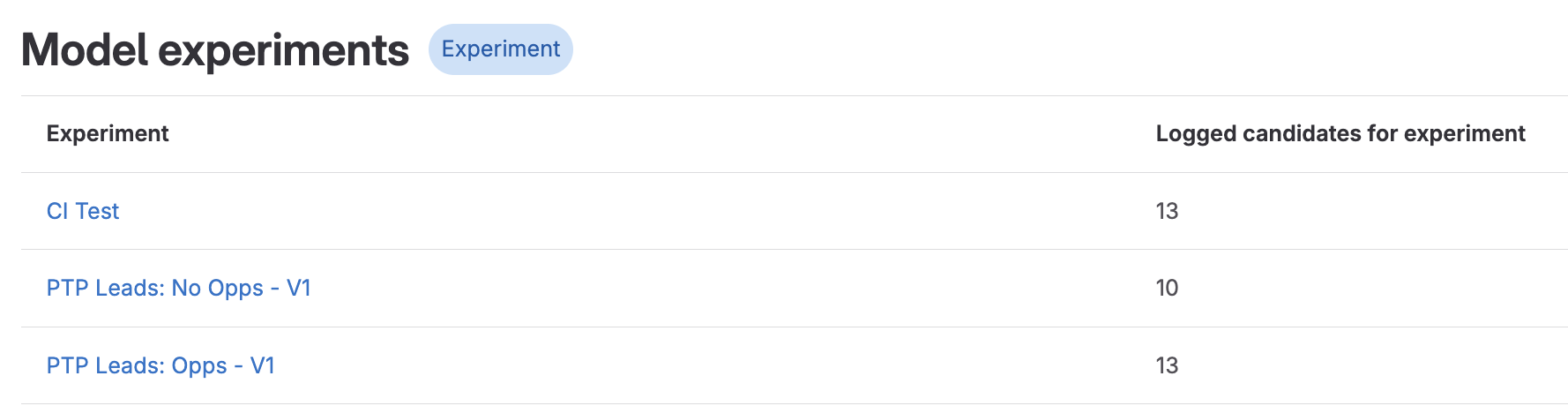 Experiments automatically logged on every CI pipeline GPU training run
Experiments automatically logged on every CI pipeline GPU training run
Each model artifact created can be traced back to the pipeline that generated it, along with its dependencies:
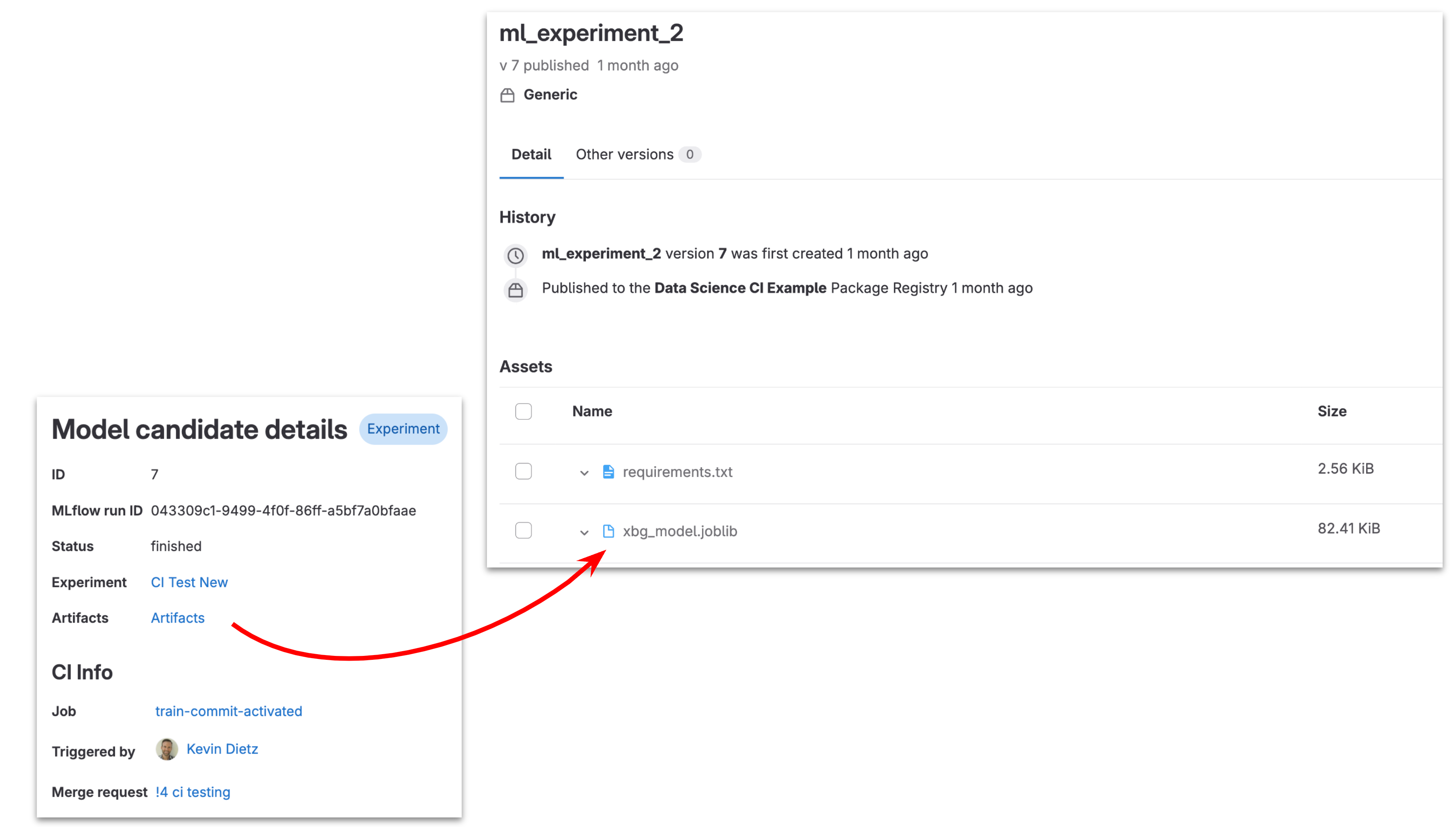 Model traceability from pipeline run to candidate details
Model traceability from pipeline run to candidate details
Putting it all together
What is machine learning without data to learn from? We also leveraged the Snowflake connector in the model training notebook and automated the data extraction whenever the respective commit triggers a training job. Here is an architecture of the current solution with all the parts described in this blog post:
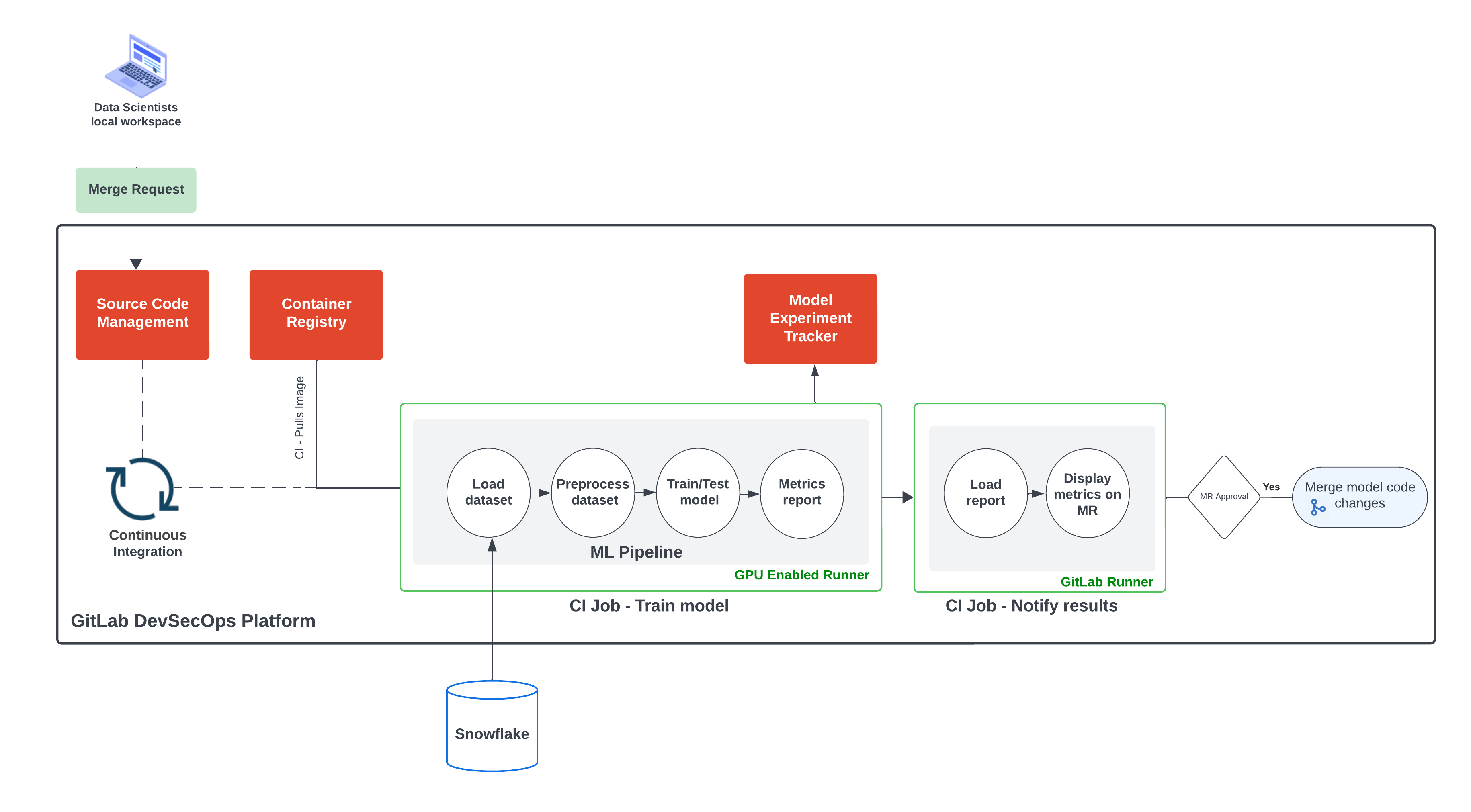 Data Science pipelines automated using GitLab DevSecops Platform
Data Science pipelines automated using GitLab DevSecops Platform
| Challenge | Solution |
|---|---|
| Prone to error due to manual steps | Automate steps with GitLab CI/CD |
| Experimentation results that are hard to replicate | Record metadata and model artifacts with GitLab Experiment Tracker |
| The long training time of machine learning models | Train models with GitLab SaaS GPU Runners |
Iterating on these challenges is a first step towards MLOps, and we are at the tip of the iceberg; in coming iterations, we will adopt security features to ensure model provenance (software bill of materials) and code quality, and to monitor our ML workflow development with value stream dashboards. But so far, one thing is sure: There is no MLOps without DevSecOps.
Get started automating your data science pipelines, follow this tutorial and clone this data-science-project to follow along and watch this demo of using GPU Runners to train XGBoost model.
See how data scientists can train ML models with GitLab GPU-enabled Runners (XGBoost 5-minute demo):
More "Building GitLab with GitLab" blogs
Read more of our "Building GitLab with GitLab" series:


