The following page may contain information related to upcoming products, features and functionality. It is important to note that the information presented is for informational purposes only, so please do not rely on the information for purchasing or planning purposes. Just like with all projects, the items mentioned on the page are subject to change or delay, and the development, release, and timing of any products, features or functionality remain at the sole discretion of GitLab Inc.
| Section | Group | Maturity | Last updated |
|---|---|---|---|
| Enablement | Geo | Viable | 2024-07-02 |
Thanks for visiting this category strategy page for GitLab Geo Replication. This page belongs to the Geo group.
Geo-replication improves the GitLab experience for geographically distributed teams.
Pulling a large Git repository can take a long time for locations geographically remote from the main GitLab instance.
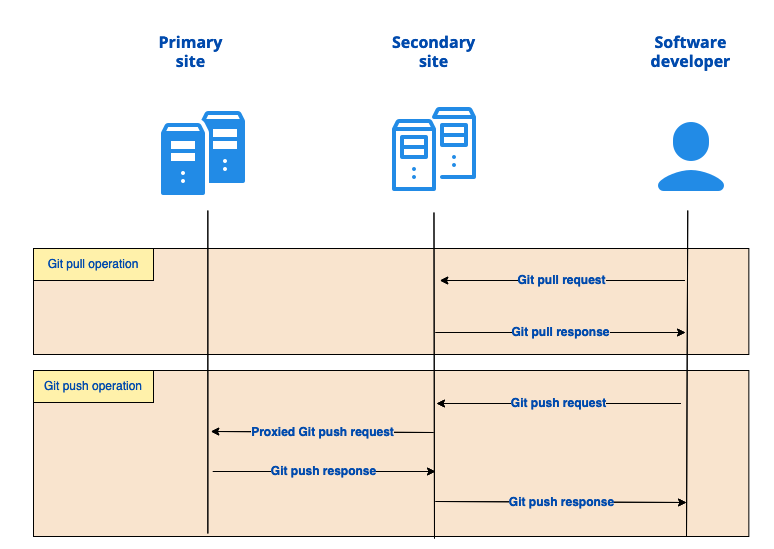
Geo-replication provides an easily configurable, replica Geo site, which can be deployed in additional regions and seamlessly accelerates the GitLab experience for nearby users. This is achieved by replicating the entire GitLab data set to the replica site in a coordinated, verifiable and coherent manner. User requests are directed to the Geo site that is closest in proximity to the user using location aware URL. Intelligent proxying techniques transparently guarantee users have access to the most recent data.
Geo replicates and verifies all core GitLab data types.
Geo-replication is also the foundational technology underpinning GitLab's Disaster Recovery solution
Please reach out to Sampath Ranasinghe, Product Manager for the Geo group (Email) if you'd like to provide feedback or ask any questions related to this product category.
This strategy is a work in progress, and everyone can contribute. Please comment and contribute to the linked issues and epics on this page. Sharing your feedback directly on GitLab.com is the best way to contribute to our strategy and vision.
As companies increasingly shift towards remote or hybrid work environments, GitLab becomes a central place for collaboration and the DevOps Platform for many customers. GitLab should offer the same great experience to users, regardless of their location.
Geo-replication will provide horizontal scaling and improved user experience for geographically distributed teams. We envision customers being able to easily spin up new Geo sites in new locations to improve the GitLab experience for their remote users. These sites can be tailored to the requirements of the team. End users interact with GitLab via a single URL and can accomplish all of their tasks without having to worry about the underpinning Geo architecture.
Geo sites will accelerate both users and CI runners, allowing loads to be distributed across the Geo sites rather than focused on a single primary site.
Systems administrators will be able to see the utilization of their secondary sites and understand their return on investment for these sites by seeing the number of read requests served, the number of CI jobs run, and the volume of data served by a secondary site. It will be possible to see the improvement in the user experience delivered by these sites such as speed of access to data, load on the primary sites, and number of unique individual users served.
As GitLab evolves, new features are developed and new data types will be created. Geo self-service framework is now mature, and all data types will be managed through this framework. The self-service framework makes it easy for these new data types to be added and empowers developers outside the Geo team to add new data types.
For more information on how we use personas and roles at GitLab, please click here.
Geo performs complex operations by scheduling tasks in the background to replicate data to the secondary sites. Geo will improve the observability of these operations for the systems administrators such that they can monitor tasks that are currently running, tasks scheduled to run in the future and tasks that have failed. For tasks that have failed, Geo will surface information in the UI that will assist in troubleshooting the root cause of the failure. Improved observability will also enhance the experience for systems administrators who are setting up their secondary site for the first time, providing immediate feedback on whether the setup was successful and replication processes are successfully underway. Failed replication can hinder the availability and reliability of a secondary site. Further, it can negatively impact the chances of successful recovery in disaster recovery scenarios resulting in the loss of data.
Today Geo accelerates access to several data types including projects, wikis, and LFS objects by serving read requests from the secondary site closest to the user accessing the data. Geo replicates many other data types. Users can benefit from accelerating more data types with two key benefits:
We will initially focus on the high-impact data types that will deliver the most value to our customers by identifying data types that are large in size and most frequently accessed such as container registries and CI job and pipeline artifacts. As part of this effort, Geo will collect statistics on data types that are proxied to the primary from the secondary sites. This will allow us to make more informed decisions as to which data types to accelerate in the future. This will open up more use cases for Geo-replication and help drive adoption.
To save bandwidth and resources, a systems administrator may want to selectively enable and disable Geo-replication for certain types of data. Currently, this is not possible unless a data type is released behind a feature flag, and this is not the case for all data types. We want to provide administrators with an easy way to enable or disable replication by data type in the Geo Administrator UI.
Configuring and managing a multi-node Geo site requires logging in to multiple nodes to perform specific steps in the correct order.
It would make administrators' jobs a lot easier if operations could be orchestrated from a single point of entry into the site and the appropriate operations performed on the sites. This will lower the technical barrier for adoption of Geo-replication.
GitLab Environment Toolkit(GET) is a good place to start and already has a lot of functionality. This is likely where we will start. It also has the ability to manage multiple sites.
Setting up Geo is highly manual and cumbersome, especially in high-availability configurations. Simplifying the installation and configuration of Geo for single and multi-node sites will remove a pain point for systems administrators and help drive adoption.
For Geo-replication only a subset of data may need to be replicated but Geo sites require spinning up the entire GitLab stack, less may be sufficient. Additionally, systems administrators can select a subset via selective sync, but they may be wrong.
We are investigating an advanced caching mode with the following properties:
GitLab is planning to roll out decomposed databases to self-managed customers. This involves splitting the main rails database into two databases main and ci improving scabality and performance. More details can be found in the blog post, Decomposing the GitLab backend database.
The main rails database is a key component that Geo replicates between Geo sites. The splitting of this database into two separate databases requires Geo to support this configuration before it is rolled out to self-managed customers. It will ensure their Geo installations will continue to work as it is transitioned to this configuration and they benefit from the improved scale and performance it brings.
It is currently possible for systems administrators to get a basic overview of the Geo status using the Geo Web UI.
Geo also publishes an extensive list of prometheus metrics. However, these metrics are not easy to consume. Publishing a Grafana dashboard would make these metrics more accessible and useful for systems administrators. The GitLab Dedicated team have already built such a dashboard. The Geo team will take over the maintanence and updating of this dashboard. We will also publish this dashboard so that customers can download and import it into their Grafana instance.
The container registry is a component that typically contains a large volume of data and is frequently accessed by CI runners. Accelerating the container registry will complement the acceleration of CI runners by allowing the runners to pull from the container registry on a secondary site, allowing the container registry to scale horizontally and distribute the load across Geo secondaries.
We are currently not planning on moving away from PostgreSQL as a backend database in favor of e.g CockroachDB or Google Spanner. This has implications for writable Geo site Geo, but for now, we will continue to support PostgreSQL.
Geo secondary sites are read-only. Customer feedback has indicated a desire for additional active active git replication. With the availability of Gitaly Cluster we may start investigating writable Geo sites at some point in FY23.
Geo will remain an asynchronous solution with loose time constraints for replications and verification.
This category is currently at the Viable maturity level, and our next maturity
target is Lovable (see our definitions of maturity
levels.
You can track the work that will move the category to Lovable in
this epic.
The top competitors for Geo-replication are
| Feature | GitHub | AzureDevOps | Bitbucket Smart Mirroring | GitLab. |
|---|---|---|---|---|
| Mirror repositories | ✅ | ✅ | ✅ | ✅ |
| Active-active replication | ✅ | N/A | ❌ | ❌ |
| Selective sync | N/A | N/A | ✅ | ⚠️ |
| UI configuration | ❌ | ✅ | N/A | ⚠️ |
| Kubernetes support | ❌ | ❌ | ❌ | ⚠️ |
| Mirror docker registries | ❌ | N/A | ❌ | ✅ |
| LFS and file upload support | ✅ | N/A | ✅ | ✅ |
| Geographic routing 1 | ✅ | ❌ | ❌ | ✅ |
| GUI Dashboard | ✅ | ✅ | N/A | ✅ |
| Request proxying | ✅ | N/A | N/A | ✅ |
✅ Fully available ⚠️ Partially available ❌ Not available N/A No information available
1 Replicas are compatible with geolocation-based DNS routing or load balancing