The following page may contain information related to upcoming products, features and functionality. It is important to note that the information presented is for informational purposes only, so please do not rely on the information for purchasing or planning purposes. Just like with all projects, the items mentioned on the page are subject to change or delay, and the development, release, and timing of any products, features or functionality remain at the sole discretion of GitLab Inc.
Enable and empower data science workloads on GitLab
GitLab ModelOps aims empower GitLab customers to build and integrate data science workloads into their software.
Over the last decade GitLab has helped companies navigate digital transformation into software companies.
Digital Transformation is about creating new opportunities for your business to drive innovation and efficiency, to improve how your teams work, and to leapfrog ahead of competitors, all with the goal of delivering new and improved customer experiences.
Every industry is undergoing a transformation. Customers are expecting more and retaining them is increasingly difficult as your competitor is now just a click away. Irrespective of your industry, technology now needs to be front and center of your offering as competition is coming from unexpected sources.
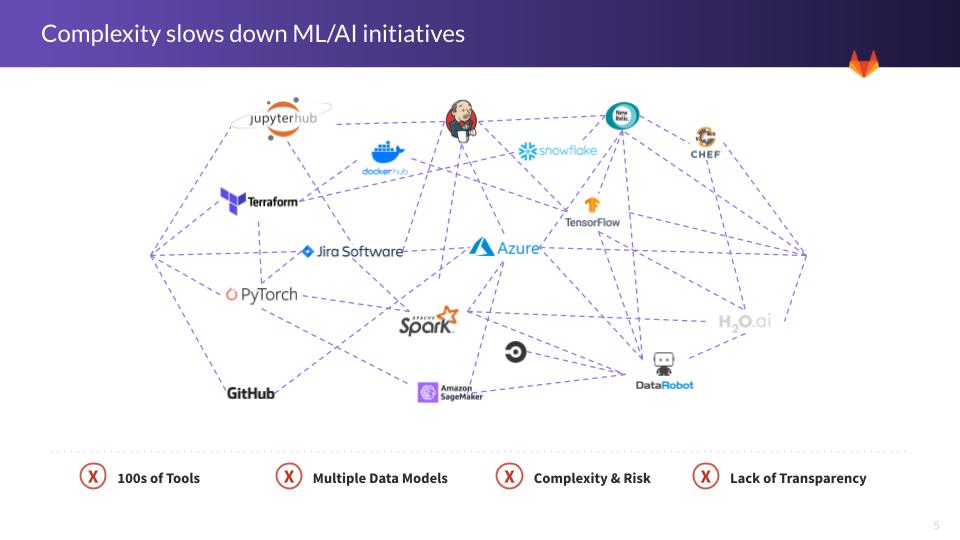
Companies are increasingly leveraging data within their businesses to power next generation software powered by machine learning (ML) and artificial intelligence (AI). The next stage of digital transformation is software companies adopting ML/AI technologies to power next generation, data rich applications. This comes with new challenges with managing the big data needed to power these algorithms, and unique challenges running AI/ML at scale including data cleaning, job orchestration, model training/testing/deployment, and observability.
Leveraging over a decade of experience with DevOps best practices, we're aiming to support businesses making this data science transformation. This section focuses on the new challenges of building these data rich, highly interactive, ML/AI applications. Our ModelOps stage will extend the GitLab platform to enrich features with data science features while also enabling customers to build ML/AI workloads with GitLab. We'll be dogfooding these capabilities in our AI-powered stage as we build GitLab Duo.
Most businesses today generate a lot of data. Data about their customers, their products, metadata and more. Businesses are literally drowning in data and struggle on to extract value from it to power next generation applications and experiences for their customers.
As businesses advance their digital transformations they increasingly create more applications that generate more and more data. This creates challenges just to manage all that data. From storing, aggregating, cleaning, organizing, and even deleting data. That's all just the management of the data, not actually doing anything with it. Many organizations also have data in many different locations, from within their applications themselves, in bespoke data stores, or possibly even the cloud. This leads organizations to build data warehouses where they can manage and unify disparate data sources. This is where the concept of Extract, Load, and Transform (ELT or ETL) derives. ELT platforms have become big businesses with organizations spending lots of money to just store and organize all their data. Data comes at a cost and thus organizations need to extract value from it, that leads to the next challenge.
With businesses generating endless data streams and spending money to store, manage, and organize it, it's easy to understand why organizations want to extract value from it. Most businesses today have internal business intelligence groups or data analysts who comb through this data looking for insights and ways to extract insights. These insights might be used to answer business questions about what product features to build next, or power next generation customer experiences. It all comes down to extracting value from data. This is usually how data science gets started within an organization.
Data analysts and data sciences within organizations work with the vast data businesses have within their data warehouses cleaning, organizing, and deriving data into more useful forms. As organizations become more data driven they tend to increase the integration of data into their customer facing applications. This introduces new software development lifecycle (SDLC) challenges. Applications that are data rich usually need connections to data, that data flows through applications which has to be managed leading to more complex software development. The most modern organizations are now even embedding real time data science into their applications further complicating software stacks. Live data flows through applications, through ML and AI models which make realtime decisions and outcomes based on the data flowing through them leading to even more complex applications. All of this introduces new challenges within the software development lifecycle (SLDC) that have to be managed by engineering teams that build, deploy, and run these customer facing applications.
Looking back over the past decade of software engineering we've seen a transition of companies going through digital transformations to become software companies. Today most companies are software companies. Part of GitLab's historical success has been helping companies streamline complex software development lifecycles into our single application DevOps platform reducing complexity and speeding up time to value. We're now seeing these software companies embrace data science with many of the same challenges as before:
Our Data Science section aims to help organizations solve these new challenges as customers add ML/AI into their applications. But it's not just our customer's software that's going through this transformation. GitLab itself is transforming our software to become more intelligent. With our ModelOps stage we're integrating machine learning and artificial intelligence into the GitLab product itself to allow Gitlab to offer AI-powered suggestions and recommendations. We're also leveraging the data our platform generates to provide new and advanced features to our platform customers. Our Anti-Abuse stage is using GitLab data within the platform to make real time decisions to keep the platform running smoothly. GitLab Duo is leveraging data across the platform to help developers become more efficient and productive. GitLab Workflow is empowering autonomous AI agents to interact with the platform and will help evolve what it means to build software.
GitLab builds GitLab with GitLab, meta right? We dogfood all our own features. As we enrich our platform with ML/AI, we experience the same challenges our customers experience building ML/AI into their applications. These insights will inform the features we build into the GitLab DevSecOps platform to support these ML/AI workloads making it easier for our customers and GitLab itself to integrate ML/AI into applications built with GitLab. It'll also help GitLab evolve faster and more efficiently in the future bringing move value to our customers, faster, and more efficiently.
The work of the Data Science section cuts across the entire GitLab DevOps platform, from our reliance on features like source code management (SCM) and CI/CD to support machine learning (ML) and artificial intelligence (AI) workloads to how we enhance platform features with ML/AI to make them more intelligent and automated. The section is unique in that the value it creates slices horizontally across all other GitLab sections and stages, providing a holistic approach to data science use cases across the software development lifecycle. ModelOps is a new component of GitLab's Data Science product strategy. ModelOps focuses on enabling Data Scientists to use GitLab effectively.
GitLab is currently investing only in MLOps, with no direct investment in DataOps. In 2025 we expect to expand our investment across the ModelOps groups.
Last Reviewed: 2024-10-05
Last Updated: 2024-10-05